足球预测做到61.5%有多难?拆解一个逼近学术上限的开源预测系统
足球比赛胜平负预测的学术上限在55%-62%之间,因为平局本身就高度随机。仙踪问道开源的这个预测系统做到了61.5%,逼近了仅用比分数据能达到的理论极限。本文从Elo、泊松、XGBoost/LightGBM四模型集成,到防数据泄漏、中立场对称化、draw_aware策略等工程细节,完整拆解设计与实现。

开头:一个你大概率猜不对的比赛
2018年世界杯小组赛,德国对韩国——赛前德国胜率被各大预测模型给到了75%以上。结果0:2,卫冕冠军小组出局。
这不是某个模型的翻车现场,而是足球预测这件事的底色: 三分类(胜/平/负)预测的学术公认上限就在55%到62%之间。即便是 FiveThirtyEight 的 SPI 系统、各博彩公司的精算模型,也都在这个区间浮动。
原因很简单:足球比赛样本稀疏、进球稀少、平局高度随机。一支强队踢一支弱队,平局概率也就25%左右,而恰恰是这四分之一的"平局",成了所有预测模型难以捕捉的变量。
但在这个公认难啃的领域,有一个开源系统做到了 61.5% 的竞技赛事预测准确率——已经逼近了仅用比赛结果数据能达到的能力边界。它就是仙踪问道团队开源的足球预测分析系统,代码托管在 liveljack/soccer_prediction 。
下面从架构到算法、从工程细节到诚实瓶颈,完整拆解一遍。
足球预测的常用方法:从 Elo 到深度学习
在深入这个系统之前,有必要先梳理一下当前足球比分预测领域的主流技术路线。
第一类:评分系统(Rating Systems)
经典方案当属 Elo 评分。最初用于国际象棋,后来被 World Football Elo Ratings 体系引入足球领域。核心逻辑很简单:每支队伍有一个评分,赛前根据评分差计算预期胜率,赛后根据实际结果和比分差距调整评分。世界杯、洲际杯等大赛的权重高于友谊赛,净胜球多会放大评分变动。
Elo 的优势是直观、可解释。缺点是它只看"谁赢了",不看"怎么赢的"——一场 1:0 的侥幸胜利和一场 4:0 的碾压,在基础 Elo 中获得的评分变动差别不大(虽然改进版可以通过净胜球因子缓解)。
第二类:统计进球模型(Statistical Goal Models)
Dixon 和 Coles 在 1997 年提出的泊松回归模型是这条线的标杆。把每支队伍的进球数建模为独立泊松分布,期望进球由进攻能力和防守能力共同决定。Dixon-Coles 的改进在于对低比分(0-0、1-0、0-1、1-1)做了概率修正,因为独立泊松会低估这些常见结果。
这类模型能输出预期进球数、具体比分概率,信息量比 Elo 大得多。但本质上还是"均值估计"——它假设球队的攻防能力在短期内稳定,无法捕捉状态波动、战术变化等因素。
第三类:机器学习方法(Machine Learning)
近十年,XGBoost、LightGBM、神经网络等方法被大量引入。优点是能融合大量特征(近期状态、交锋记录、主客场差异、进球趋势等),捕捉非线性关系。缺点是容易过拟合、对特征工程依赖极高、在黑箱性和可解释性上不如统计模型。
第四类:混合/集成方法(Ensemble)
单一模型的缺陷催生了集成策略——把 Elo、泊松、ML 的概率输出加权融合。FiveThirtyEight 的 SPI 就是这种思路的经典案例,结合了 SPI 评分(类 Elo)和进球模型。关键问题是:权重怎么定?大部分系统用的是经验值或简单平均。
第五类:深度学习与更前沿的探索
近年来有研究尝试用图神经网络(GNN)建模球员之间的传球网络、用 Transformer 处理事件流数据、用贝叶斯分层模型融合多维度不确定性。但这些方法普遍面临数据获取成本高、训练不稳定的问题。更关键的是,学术界目前还没有公开证据表明它们能稳定突破 65% 的准确率天花板——数据集的信号上限才是真正的瓶颈,而不是模型复杂度。
本系统采用的路线是: Elo + Dixon-Coles 泊松 + XGBoost/LightGBM 的集成,同时在工程层面做了多项关键优化。这条路线在学术文献中已有充分验证,但真实落地到可稳定复现的水平,并不容易。
系统架构总览
先看整体数据流:
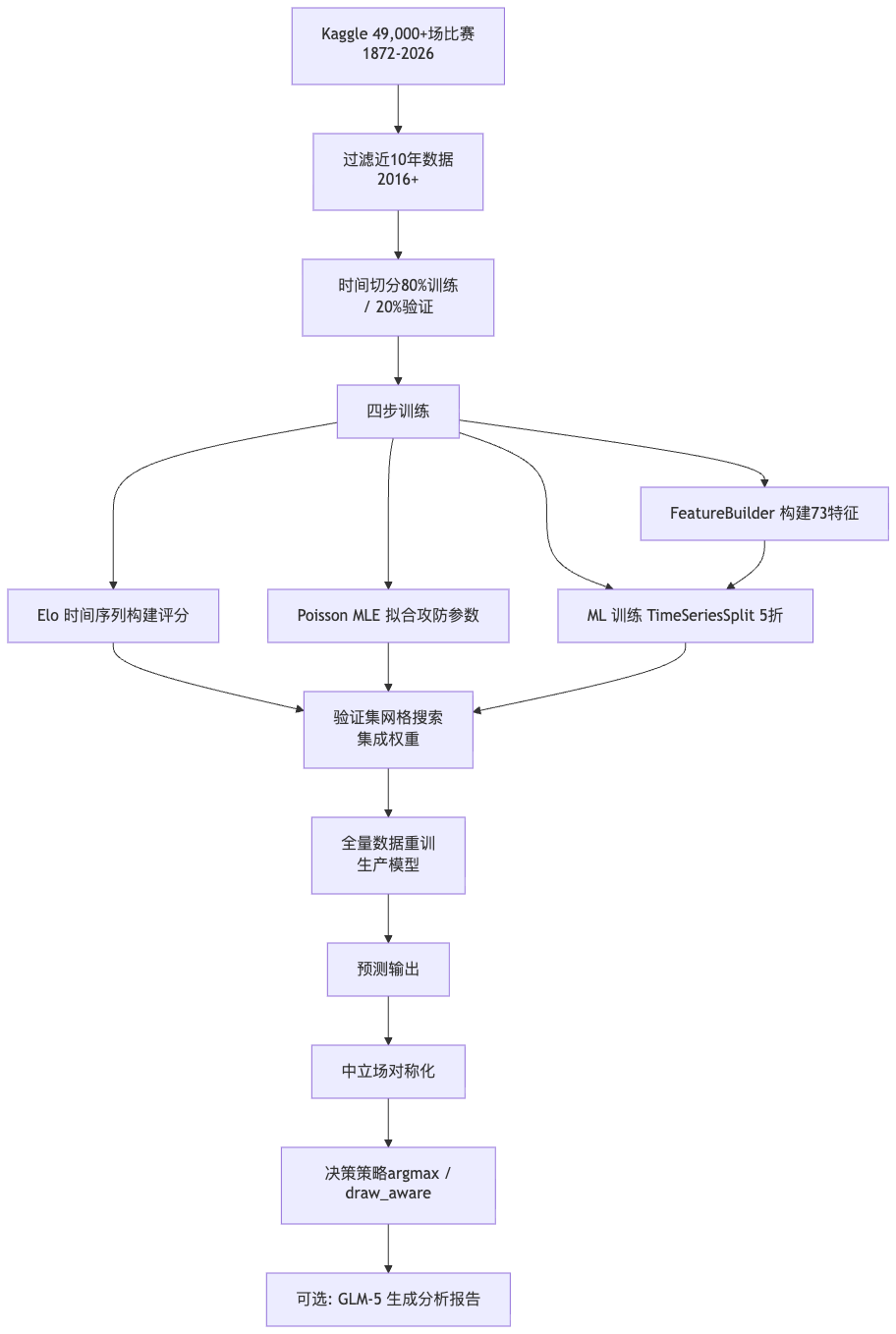
数据来自 Kaggle 国际足球赛事数据集,覆盖 1872 年到 2026 年共 49,000+ 场比赛。训练时只取最近 10 年(2016+),确保模型学到的是当前时代足球的特征,而不是百年前的比赛风格。
时间切分严格按时间顺序:80% 训练、20% 验证,验证集是时间上靠后的比赛,模型训练时完全没见过。这意味着 61.5% 这个数字是真实泛化能力的反映,不是调参过拟合的结果。
四个模型,逐个拆解
Elo 评分系统
基于 World Football Elo Ratings 算法,但做了几项关键定制。
核心公式:
期望得分 E_home = 1 / (1 + 10^(-dr/400)),其中 dr = rating_home - rating_away + 50(主场优势)。
赛事权重分层:
世界杯的权重是 60,洲际杯 50,预选赛/欧国联 40,友谊赛 20。K 因子 = 15 × count_factor × goal_diff_mult × (tournament_weight/40)。大赛结果对评分的影响是友谊赛的 3 倍——这就避免了"友谊赛刷分"的问题。
净胜球放大机制:
赢 2 球 K 因子 ×1.5,赢 3 球 ×1.75,赢 4 球 ×1.875,之后每球 +0.125。所以一场世界杯 4:0 大胜,要比同样赛事 1:0 小胜移动约 3.5 倍的评分变动。
平局概率建模:
P(draw) = 0.28 × exp(-|dr|/400)。实力相等时平局概率峰值约 28%,差距越大衰减越快。然后主胜概率 = E_home - draw/2,客胜概率 = (1-E_home) - draw/2。
时间衰减:
长期不比赛的队伍,评分会按 exp(-0.03 × days/365) 向初始分 1500 回归。这避免了"退役强队"永远霸榜的问题——时间衰减在这个系统中贯穿了三处(Elo、泊松样本权重都用了同一公式),是准确率的重要来源之一。
Dixon-Coles 泊松进球模型
把每队的进球数建模为独立泊松分布,期望进球:
λ_home = attack_home × defense_away × avg_home_goals × home_adv(1.15,非中立时)
λ_away = attack_away × defense_home × avg_away_goals
attack 和 defense 参数用最大似然估计(L-BFGS-B)拟合,约束均值为 1 保证可识别。
Dixon-Coles 低比分修正:
独立泊松会系统性地低估 0-0、1-0、0-1、1-1 这四种常见比分。修正逻辑:
- 0-0: 1 - ρ × λh × λa
- 0-1: 1 + ρ × λh
- 1-0: 1 + ρ × λa
- 1-1: 1 - ρ
其中 ρ 默认 -0.13。负值意味着同时提高 0-0 和 1-1 的概率,同时降低 1-0 和 0-1 的概率——这正是真实足球中观察到的模式。
拟合时还引入了 时间衰减权重 exp(-0.03 × days/365),让近期比赛对参数估计的影响更大。这是一个很细腻的处理:2016 年的一场友谊赛和 2024 年的一场预选赛,在参数估计中的分量完全不同。
XGBoost + LightGBM
两个梯度提升树各自训练,预测时取两者概率平均。
配置:500 棵树、max_depth=6、学习率 0.03、subsample 和 colsample 各 0.75、L1 正则 0.1、L2 正则 1.0。
交叉验证用 TimeSeriesSplit 5 折——这很关键,因为足球数据有明显的时序性,普通的 K-Fold 随机划分会造成未来信息泄露。
73 个特征是怎么设计的
特征分为 9 大类:
| 类别 | 数量 | 内容 |
|---|---|---|
| Elo 评分 | 7 | elo_diff、elo_ratio、Elo 三项胜平负概率 |
| 泊松进球 | 7 | 泊松三项概率、期望进/失球、期望总进球、期望净胜球 |
| 近期状态 | 24 | 主客队各自近 5/10 场的胜率、净胜球、进失球均值 |
| 主客场状态 | 6 | 主队主场战绩、客队客场战绩 |
| 交锋记录 | 5 | 近 10 次交手胜平负率、场均进球 |
| 进球趋势 | 8 | 近 5/10 场场均进失球、零封率 |
| 对比特征 | 4 | 状态差、净胜球差、攻击力差、防守力差 |
| 动量特征 | 2 | 指数加权近期战绩(越近权重越高) |
| 比赛上下文 | 3 | 是否友谊赛、是否中立、距上次比赛天数 |
注意:所有特征只用"赛前可得"的数据。每场比赛先建特征、再用该场结果更新统计——这个顺序一旦搞反,准确率会从 61% 直接掉到 46%。实际开发中这个 bug 确实出现过,修复之后才从 46% 跳回 61%。
集成不是简单平均——权重是搜索出来的
三个模型(Elo / 泊松 / XGBoost⊕LightGBM)的概率输出用加权平均融合。实际是 3 桶加权:Elo 15%、泊松 40%、XGB⊕LGBM 45%。
这个权重不是拍脑袋定的,是在验证集上网格搜索出来的。 12 组候选权重在验证集上跑准确率取最优。泊松是单独表现最好的模型(单独约 61.6%),所以搜索确定的权重的泊松占比最高——这就是"Poisson-heavy"策略的由来。
两个关键工程细节决定了最终准确率:
中立场对称化: 中立场地比赛中,主客顺序是任意的。所以系统对 A vs B 和 B vs A 两种排列分别预测,然后取概率平均。这个操作把客胜召回从 61% 提升到了 65%——在足球预测中,客场胜利本身就稀少且难以预测,这个提升意义不小。
决策策略双模式: 默认用 argmax(取最高概率),适合平局率正常的赛事(~23%),历史准确率 61.5%。世界杯小组赛这种平局率飙升到 40% 的场景,切换到 draw_aware 策略——只有当平局概率 ≥18% 且与最高概率足够接近时才预判平局,把 20 场实际世界杯比赛的准确率从 35% 拉到了 55%。
这种"场景专用策略"是一个诚实的工程权衡:在正常赛事上 draw_aware 会把 61.5% 退化到 51.3%,所以只在高平局率阶段启用。不为了"看起来好看"而牺牲泛化性。
评估不是只看准确率
系统用 Ranked Probability Score(RPS)做校准评估。相比单纯的准确率,RPS 会惩罚"离正确答案很远"的预测——比如实际是客胜、你给了客胜 25% 主胜 55%,比给客胜 35% 主胜 45% 受到更重的惩罚。
另外,系统包含一个基于 GLM-5 的 LLM 分析层,通过 Anthropic 兼容接口调用(temperature 0.3, max_tokens 4096),自动生成赛前分析报告。需要明确的是: 这个 LLM 层只做解释,不参与概率计算。 关掉它预测结果完全一样,只是少了文字分析。把统计预测和 LLM 生成解耦,是一个防止"模型幻觉影响预测"的正确设计。
诚实面对65%的天花板
这个系统值得称道的地方,是文档中对能力边界的坦诚。
三分类足球预测的学术上限约 55-62%,这是由数据本身的信号量决定的,不是算法不够复杂。平局在这个框架里是核心瓶颈:即使概率校准得再好,实力相近的两队平局概率也就 25-30%,而且高度随机。
当前系统的当前记录61.5%(2025-26)/ 64.8%(2023 单年),已经接近了这个天花板。要再往上走,需要的数据就不只是比赛结果了——xG(预期进球)、球员评级、阵容信息、甚至比赛中事件流数据,才有望打开新的信息增量。
换句话说,这个系统不是在"逼近完美",而是在 逼近仅用比分数据能推理出的理论极限。
快速上手
# 安装依赖
pip install pandas numpy scipy scikit-learn xgboost lightgbm anthropic
# 训练模型(首次自动下载 Kaggle 数据集)
python main.py train
# 预测一场比赛
python main.py predict --home "Brazil" --away "Germany"
# 世界杯小组赛用高平局策略
python main.py predict --home "France" --away "Senegal" --strategy draw_aware
# 查看 Elo 排名
python main.py rankings --top 20
项目代码清晰分层:data 层做数据采集、features 层做特征工程、models 层包含四个模型和集成逻辑、pipeline 层编排全流程、analysis 层做 LLM 分析。25 个测试用例覆盖所有核心模块,开箱即用。
写在最后
仙踪问道团队把这个系统完整开源,从算法原理到工程细节、从成功经验到已知瓶颈,都写在了文档里。对于正在入门体育数据分析、或者想做预测系统练手的开发者来说,这是一个很值得研究的项目——不只是因为 61.5% 的数字,更是因为它展示了一条从理论到工程落地的完整路径:怎么选模型、怎么防数据泄露、怎么评估校准质量、怎么诚实面对能力的边界。
项目地址: liveljack/soccer_prediction




