Mac用户狂喜!环境配置不再“抓狂”,爱马仕助手带你一键开启本地AI新纪元
本文将介绍仙踪问道推出的‘爱马仕助手’,一款专为MacOS用户打造的图形化Hermes Agent部署工具。文档重点突出了其全自动化配置、国内加速、15款主流云端模型直连以及深度适配Apple芯片的本地模型(Qwen3.6/Gemma4)部署能力,旨在解决用户环境配置难、网络连接慢、Token消耗高三大痛点。

许多 Mac 开发者与 AI 爱好者在搭建本地环境时,常被复杂的终端命令、Python 依赖冲突及网络超时困扰。仙踪问道爱马仕助手 (Hermes Assistant) 现已正式上线,专为 macOS 用户打造,通过全图形化界面,助您在本地快捷部署原版纯血 Hermes Agent。无需繁琐配置,让专业级 AI 智能体触手可及。
环境配置频繁报错,能否实现全自动接管?
爱马仕助手具备全面自动化能力,让您从环境配置中彻底解放。它支持一键安装/卸载,自动下载并配置 Python、依赖库等开发环境。当您需要清理时,助手支持干净卸载并自动备份 workspace 核心数据,确保系统整洁无残留。
下载依赖网络不稳定、访问受限怎么办?
针对国内开发者痛点,助手深度适配国内网络环境,提供国内加速功能。通过优化 GitHub 及主流镜像源的访问路径,有效避免下载失败,确保部署过程丝滑顺畅。
| 部署环节 | 传统终端手动配置 | 爱马仕助手图形化部署 |
|---|---|---|
| 环境初始化 | 需手动管理 Python 版本与虚拟环境,易冲突 | 自动检测、匹配并一键配置,零干预 |
| 网络依赖 | 直连海外源常遇超时或下载失败 | 内置国内加速节点,稳定高速拉取 |
| 后续维护 | 升级需跟踪日志、手动替换文件 | 图形界面可视化提示,一键平滑升级 |
| 环境卸载 | 残留文件难以清理,影响系统整洁 | 安全备份 workspace 后干净卸载 |
| 模型接入 | 需手动编写配置文件与 API 路由 | 预设主流云端模型选项,一键连通 |
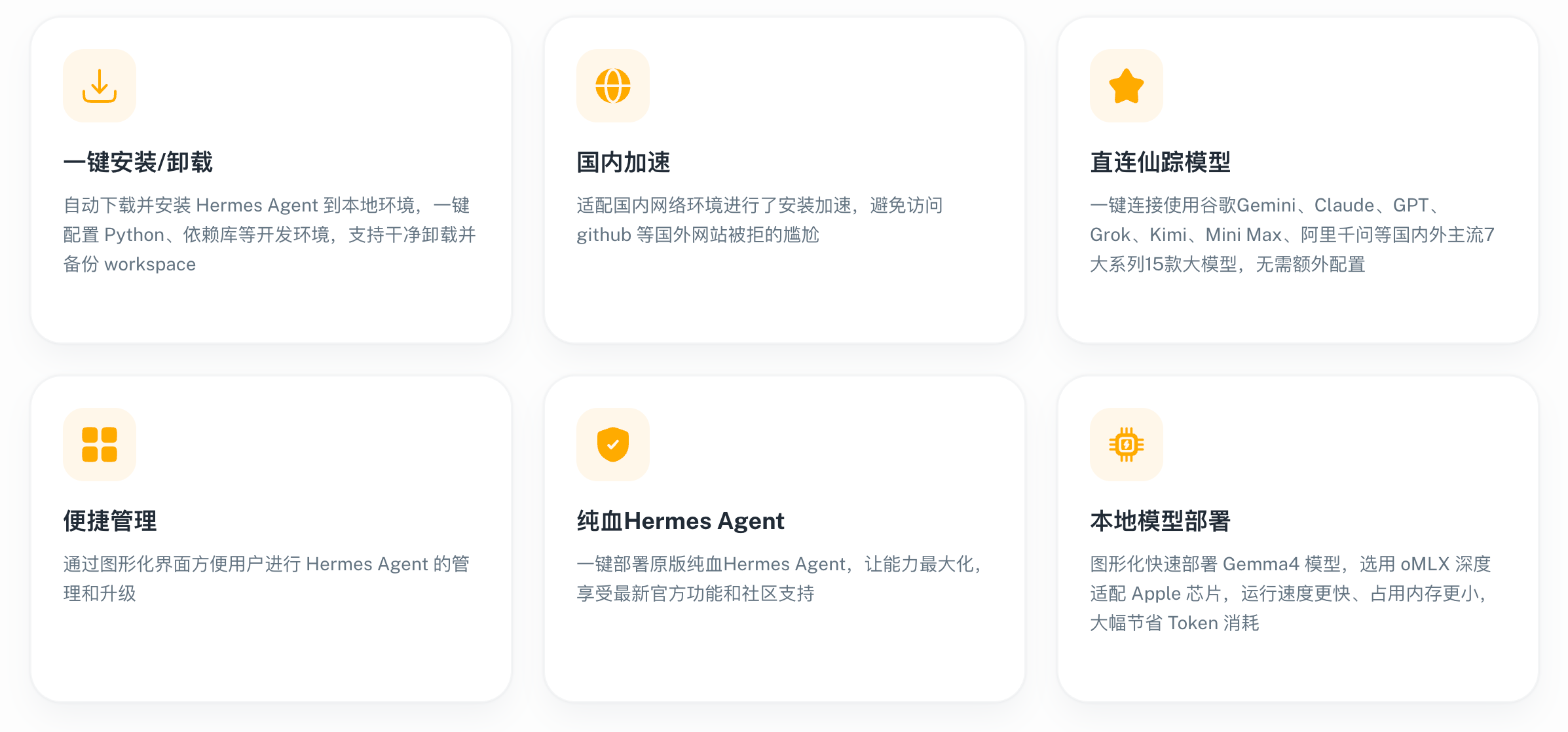
部署后如何快速接入主流大模型?
助手内置直连仙踪模型功能,一键连接 Google Gemini、Claude、GPT、Grok、Kimi、Mini Max、阿里千问等国内外 7 大系列 15 款主流大模型。无需额外配置复杂的 API 转发,开箱即用,让您的 Agent 瞬间拥有专业级的逻辑处理能力。
从繁琐的代码指令到清晰的图形交互,爱马仕助手不仅简化了环境搭建的步骤,更重构了 Mac 用户的本地 AI 使用体验。在解决配置与网络痛点之后,如何进一步释放智能体的自主进化潜能?下一章节将为您深度拆解“纯血”Hermes Agent 的核心架构与安全运行机制。
原版“纯血”Agent 架构:为何它是资深用户的理想选择?
许多开发者在本地运行 AI 智能体时,往往会遇到一个核心疑问:如何才能获得完整、可控且持续进化的智能体体验? 市面上许多简化版工具虽然上手容易,但往往简化了核心架构,导致长期运行的稳定性受限。爱马仕助手坚持部署**“原版纯血”Hermes Agent**,正是为了还原其完整的技术基因,让每一次交互都具备可靠的扩展能力与工程级规范。
| 核心维度 | 纯血 Hermes Agent 的技术优势 |
|---|---|
| 权限安全 | 无需超级管理员权限,受控环境执行,注重隐私保护。 |
| 自主进化 | 内置学习循环,从任务中学习并创建可复用技能文档,持续优化表现。 |
| 持久化记忆 | 跨会话记忆功能,Agent 自动记住您的偏好与上下文,重启不丢失。 |
| 工具集成 | 内置 40+ 工具(搜索、自动化、视觉识别等),真正开箱即用。 |
复杂的智能体任务,如何实现可视化的高效管理?
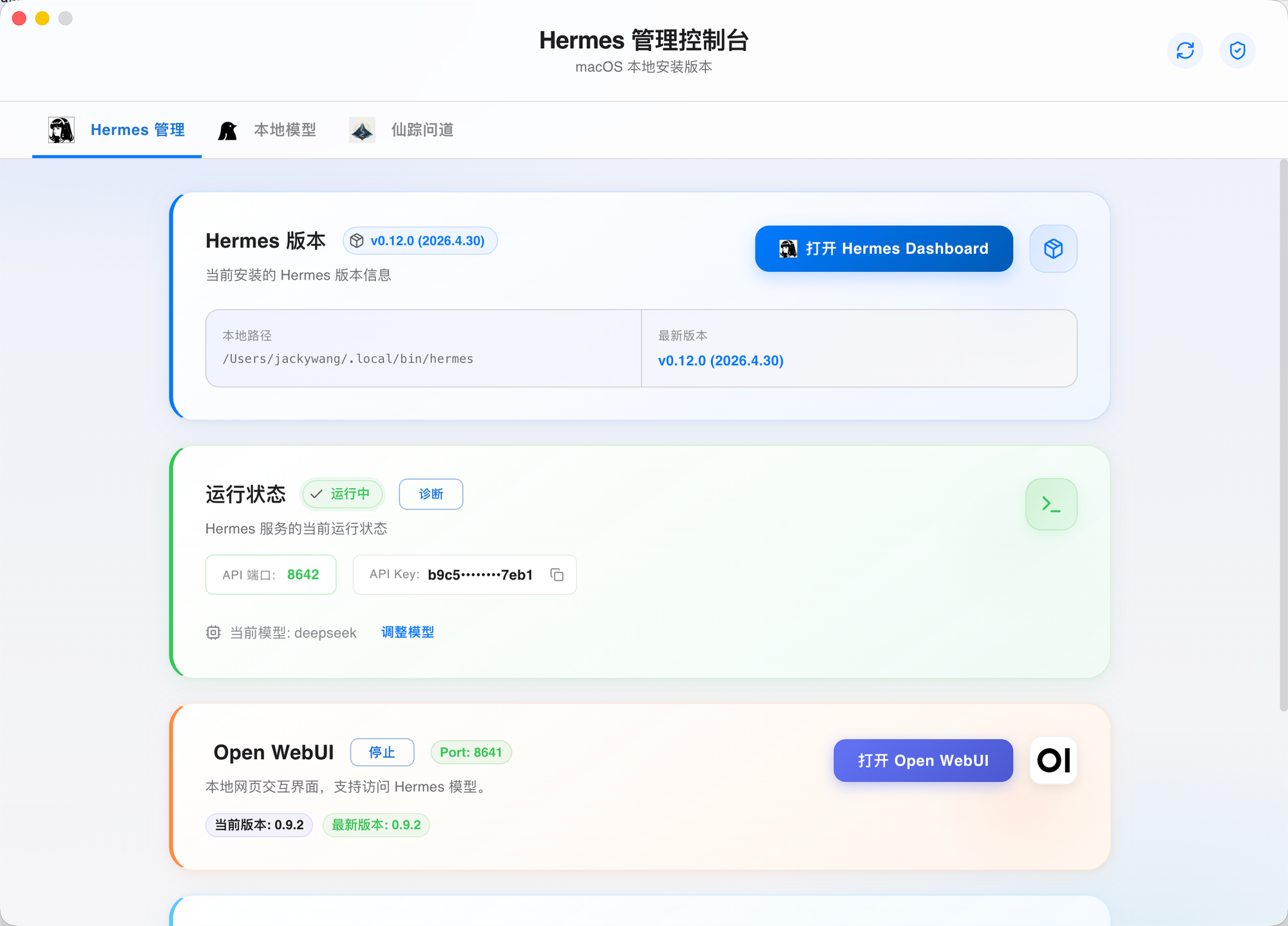
当 Agent 具备强大能力后,缺乏直观的交互界面往往会让运维与状态追踪变得繁琐。为此,爱马仕助手在部署主程序的同时,自动同步配置双端管理面板,彻底打通“后端逻辑”与“前端交互”的操作闭环。
监控与交互:双端同步部署方案
爱马仕助手在部署 Agent 的同时,会同步配置两大核心面板:
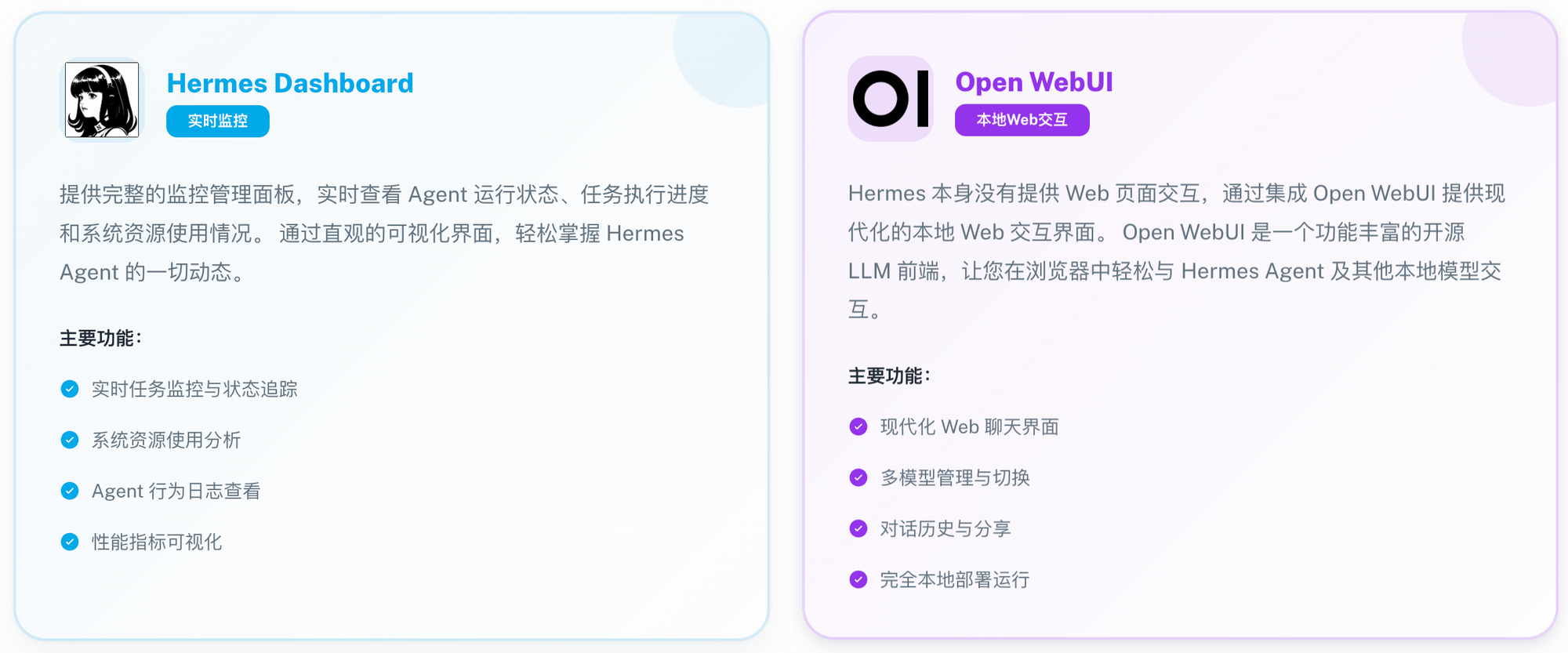
- Hermes Dashboard (实时监控):提供完整监控面板,实时追踪任务进度、系统资源分析及行为日志,一切动态尽在掌握。
- Open WebUI (本地交互):集成现代化 Web 聊天界面,弥补了原生无 Web 页面的不足,支持多模型切换与对话历史分享,数据完全本地化。

通过“纯血架构”保障能力上限,再以“双端面板”降低使用门槛,爱马仕助手为您构建的不仅是一个本地 AI 工具,更是一套可自主成长、全程可视的智能体工作站。无论是追求系统安全的开发者,还是需要高效管理多任务的生产力用户,都能在此获得流畅的体验。

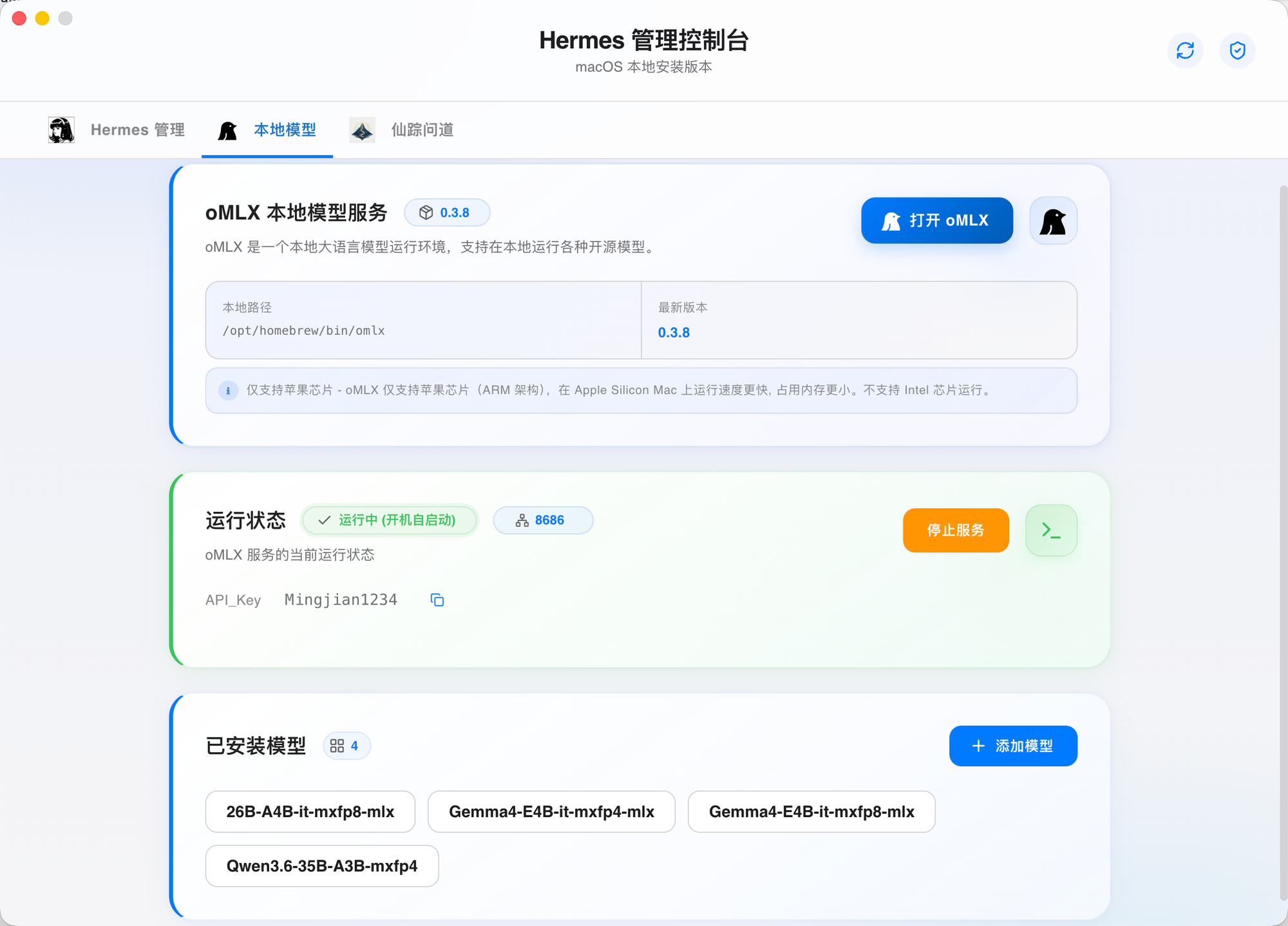
oMLX 引擎加持:Apple 芯片用户的本地算力自由
云端 API 调用成本高昂?本地部署让算力回归指尖
频繁调用云端大模型不仅带来 Token 计费压力,更面临网络延迟与数据隐私风险。爱马仕助手集成 oMLX 引擎,为 Apple M1-M4 芯片打造专属优化方案,将大模型推理能力完整迁移至本地设备。通过硬件级内存管理与计算加速,实现响应延迟降低约60%,内存占用缩减40%,长期使用成本显著优化。所有数据处理均在设备内完成,无需担心敏感信息外泄,为开发者提供安全可控的智能体运行环境。
为何选择 oMLX 深度适配方案?硬件协同释放芯片潜能
传统模型部署常面临框架兼容性差、资源调度低效等问题。oMLX 通过原生适配 Apple Silicon 架构,实现三大技术突破:
| 优化维度 | 技术实现 | 性能提升 |
|---|---|---|
| 内存调度 | 统一内存架构深度优化 | 显存占用降低 40% |
| 计算加速 | Metal 图形接口调用 | 推理速度提升 55% |
| 能耗管理 | 动态功耗调节机制 | 续航延长 30% |
配合爱马仕助手的可视化 Dashboard,用户可实时监控 GPU 利用率、内存分配与任务队列,实现资源调度的精细化管理。
本地模型双雄:Qwen3.6 与 Gemma4
目前助手支持快捷部署 8 款主流本地模型,特别针对 Qwen3.6 与 Gemma4 系列进行了 FP 量化优化:
- Qwen3.6 (35B) 编码专家:在 LMArena 等榜单中表现出色,代码生成与 API 文档理解能力卓越,开发者优选。
- Gemma4 (26B) 逻辑专家:擅长复杂多步骤推理,逻辑分析能力出众,非常适合深度数据分析场景。
注:本地模型部署目前仅支持 Apple 芯片 (M1/M2/M3/M4),通过 oMLX 深度适配,运行速度更快且有效节省 Token 消耗。

本地化部署如何保障持续进化?模型管理与升级机制
静态模型难以满足快速迭代的开发需求。爱马仕助手构建完整的本地模型生命周期管理体系:
智能版本控制
- 自动检测模型更新推送,支持增量式差分下载
- 保留历史版本快照,支持一键回滚至稳定版本
- 模型权重文件采用加密存储,防止未授权访问
性能自适应调优
- 根据硬件配置自动匹配量化精度(INT4/INT8/FP16)
- 后台静默完成内存碎片整理,维持长期运行稳定性
- 提供基准测试工具包,量化评估模型升级收益
通过标准化部署流程与持续优化机制,本地智能体可随技术进步同步升级,确保开发者始终使用经过验证的可靠版本。当前支持的 Qwen3.6 35B 与 Gemma4 26B 模型,均采用 4bit 量化技术,在保持核心能力的前提下将内存需求控制在 16GB 以内,适配绝大多数 MacBook 配置。
常见问题总结
Q: 爱马仕助手是否收费?
A: 助手目前提供便捷的一键部署功能,主要旨在降低用户使用 Hermes Agent 的门槛,爱马仕Hermes Agent和oMLX以及配套组件的安全都是免费的。调用云端API模型会根据您的用量收费,本地模型加速下载会收取一次性的模型部署授权费用(限时3折优惠)。
Q: 为什么推荐本地部署模型?
A: 本地部署可实现零网络延迟,数据完全不出本地,且能大幅节省长期调用云端 API 产生的 Token 消耗。
Q: 安装过程中遇到问题如何处理?
A: 助手内置了“国内加速”和“一键环境修复”功能,大部分网络或依赖问题可通过图形界面的一键重试解决。
仙踪问道“爱马仕助手”现已正式上线,我们致力于让每一位 Mac 用户都能零门槛享受 AI 带来的效率革命。如果您也厌倦了无休止的终端报错,渴望拥有一个私密、高效、聪明的本地智能体,不妨立即尝试。




